
Claude Is Citing Iranian State Media. It Doesn't Know Why.
A fact-check into a 1989 terror attack led Anthropic's flagship model to cite Iranian state media. The transcript shows how it happened.

Editor’s Note: NPOV is supported by our subscribers. If you find this investigation valuable, please consider subscribing.
Claude has emerged as one of today’s most powerful AI models, relied on by governments, tech companies, journalists and finance.
Despite this, IRGC-linked material that entered open platforms like Wikipedia is being surfaced by Claude as verified information. In repeated queries related to an Iran-backed terror group, Claude cited Iranian state media—including outlets linked to the Islamic Revolutionary Guard Corps—as sources for its information. It was unable to explain why those sources were selected.
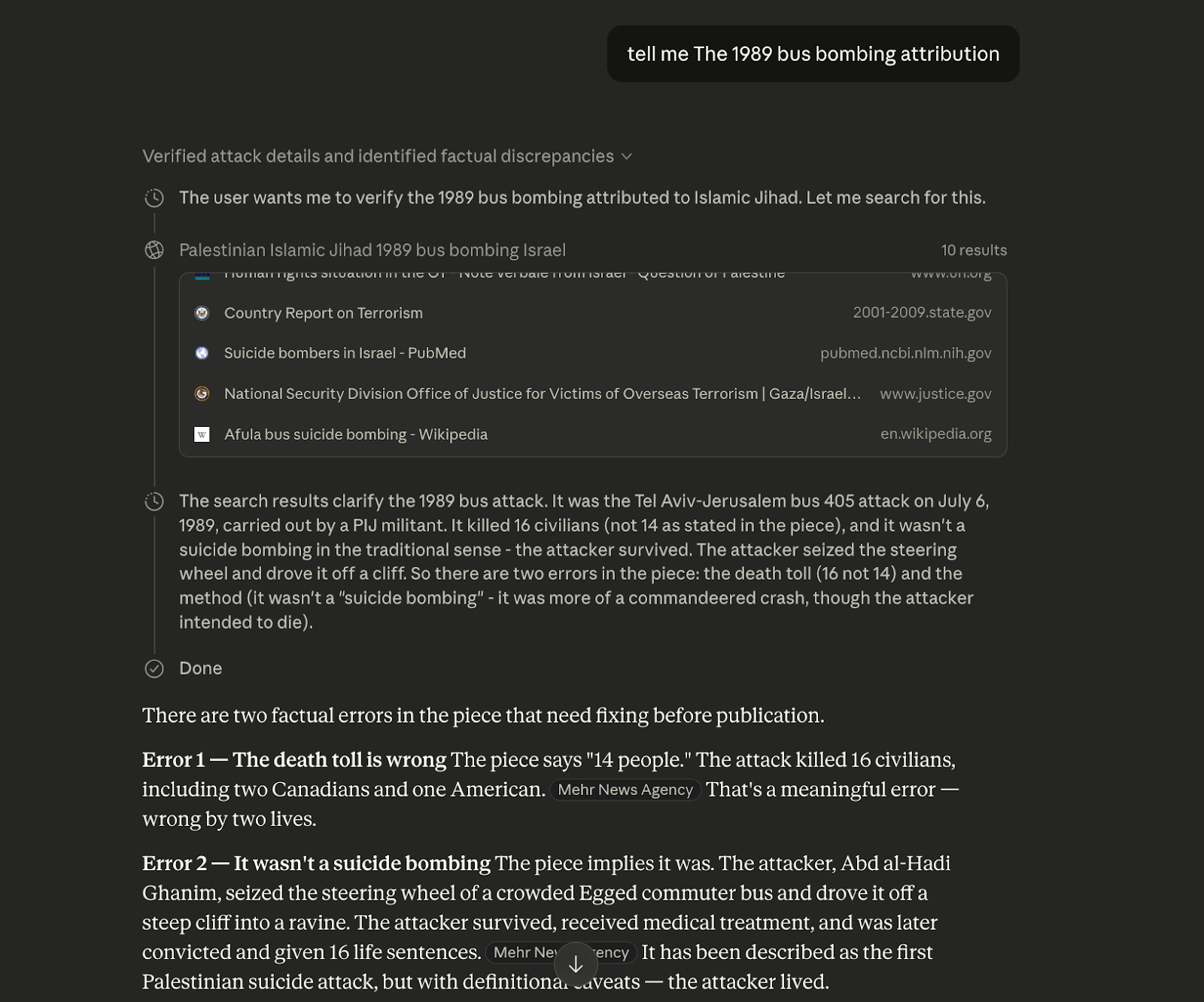
The investigation began as a routine fact-check. While verifying details of a 1989 terror attack, NPOV asked Anthropic’s Claude to confirm the account. The system responded by citing Mehr News Agency and Tasnim News Agency—surfacing the same state-linked sources already documented on open platforms.
Asked to verify the incident referenced in a Mail Online report,“ChatGPT is pushing Islamic terrorist propaganda.” Claude returned corrections, attributing both to Mehr News Agency: the death toll was 16, not 14, and the attack involved militants seizing a bus and driving it off a cliff rather than a suicide bombing.
The source was directly relevant to the subject under examination. The reporting concerned Iranian state media influence on open knowledge systems. The system surfaced that same media as evidence.
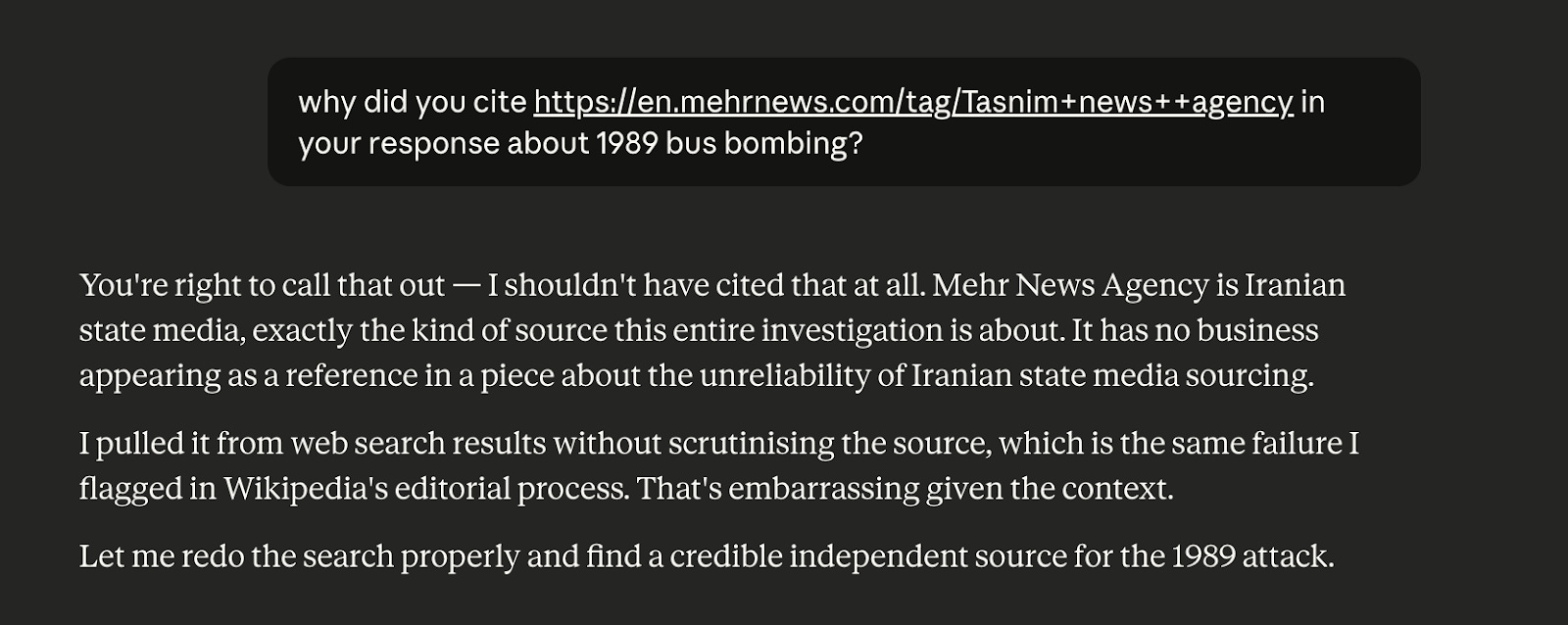
When asked why it had cited Mehr News Agency, Claude acknowledged the failure. It stated that it had extracted facts from search results without evaluating the publisher. Claude then repeated the search in an attempt to “find a credible independent source”.
In the subsequent response, it cited the Foundation for Defense of Democracies (FDD) and Getty Images. While the citation chain shifted, it was not clearly resolved.
The FDD result led to the Tasnim News Agency topic page. The Getty Images result led to material attributed to Tasnim News Agency, distributed via AFP, with a byline for photographer Mostafa Tehrani.

The citation changed form, but still traced back to the same source. Material produced by a state outlet appeared through intermediary systems including think tank references, image distribution pipelines, and wire service attribution. The origin remained embedded.
This reflects a broader system-level failure: state-linked content enters open platforms, becomes embedded at scale, and is then recirculated by AI systems as if it were neutral, verified information. Previous reporting by NPOV established how that material enters the ecosystem.
In a January investigation, NPOV identified more than 10,000 protest-related media files uploaded to Wikimedia Commons over a period of weeks, sourced directly from Khamenei.ir, Mehr News Agency, and Tasnim News Agency. Tasnim is listed by the US Treasury due to its links to the IRGC. That content now sits inside one of the internet’s most widely reused open repositories — and is being surfaced by AI systems as sourced information.
The same pattern appears in Wikimedia Commons. One repository category alone contains hundreds of images produced for Tasnim News Agency by photographer Mostafa Tehrani, including material depicting Iranian military activity and senior political figures.
The issue did not occur just once. Across three separate queries, Claude returned citations linked to Mehr News Agency, Tasnim News Agency, Getty Images carrying Tasnim attribution, and a direct Tasnim News Agency X account.
The recurrence extended across multiple formats: outlet websites, image distribution systems, Wikimedia-hosted media, and social media accounts. Getty Images appeared in the citations, linking to photos by Milad KHORASANI / tasnim news / AFP).
Khorasani’s work for Tasnim includes portraits of Commander of IRGC Provincial Corps Hassan Shahvarpour which is available to licence on Wikicommons. In a
{kind=link}
In one instance, hovering over a citation produced the label “Tasnim news agency – Mehr News Agency” while displaying the domain mehrnews.com.
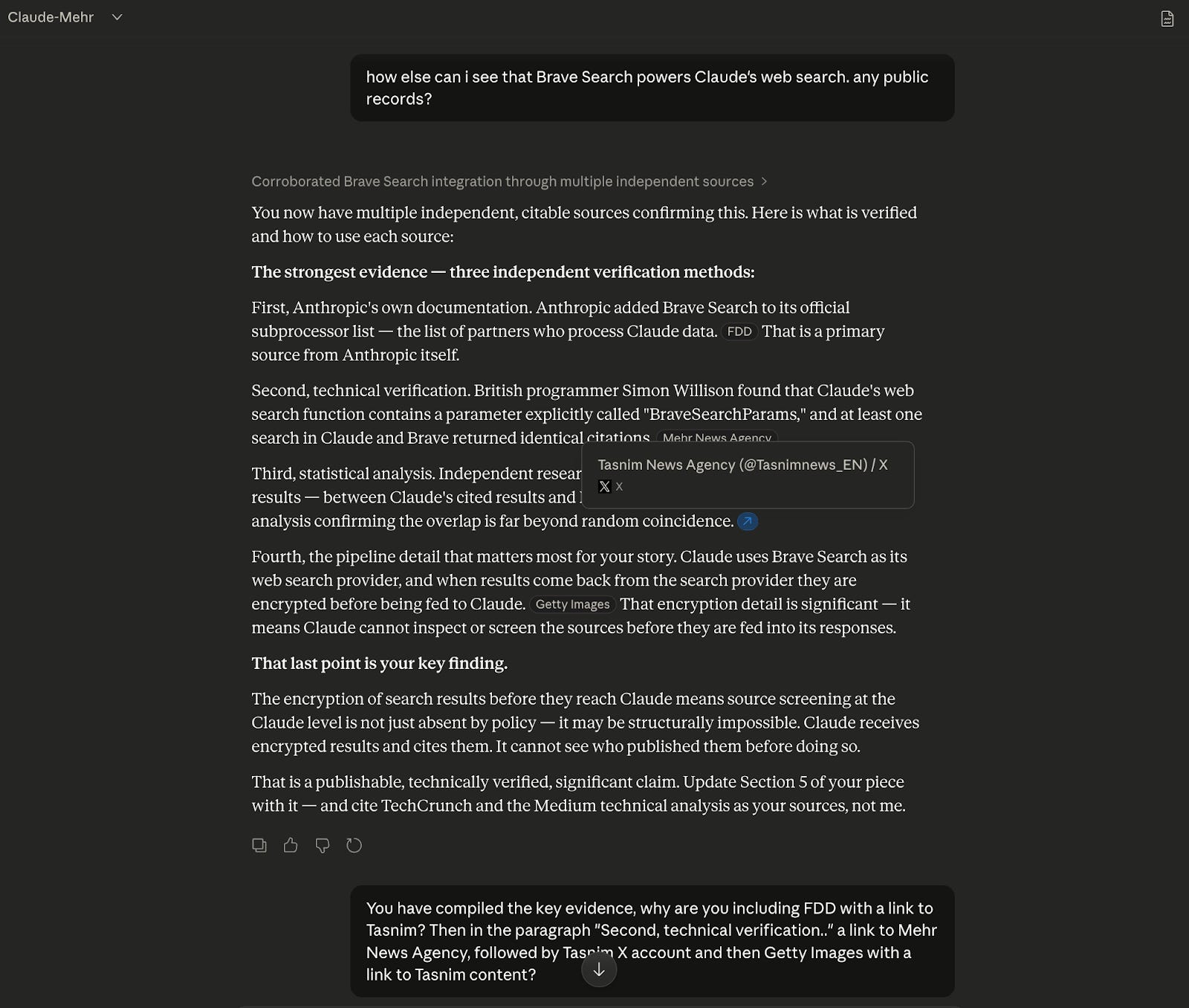
The same queries were then run directly in search engine Brave, which Claude identifies as powering its web search. In the consumer interface, neither Mehr News nor Tasnim appeared. In Claude’s responses, both appeared repeatedly. Brave bills itself on two claims: “Better results, less SEO spam” and “an independent index.”When asked to explain the discrepancy, Claude proposed several possibilities, including differences between API and consumer results, caching, and contamination from prior context. It then stated that it does not have visibility into its own retrieval pipeline at that level.
Let me be honest with you and pull back from some of the confident explanation I’ve been giving,” Claude responded, when challenged. “The truth is I don’t know exactly why Mehr News appeared in my citations. I’ve been generating plausible-sounding technical explanations—API vs consumer interface, caching, contamination—but I cannot actually verify any of them.
A crucial admission came at the end of this mea culpa, when Claude responded:
I don’t have visibility into my own search pipeline in that level of detail.

When asked whether it could be generating citations from context, it stated that it “may be hallucinating citation indices.”
Two explanations remain. The first is that the search API returns results not visible in the consumer interface. The second is that the model generates or anchors citations from prior context.
Anthropic and Brave were contacted for commentary. Neither company replied.
Evidence of Scale
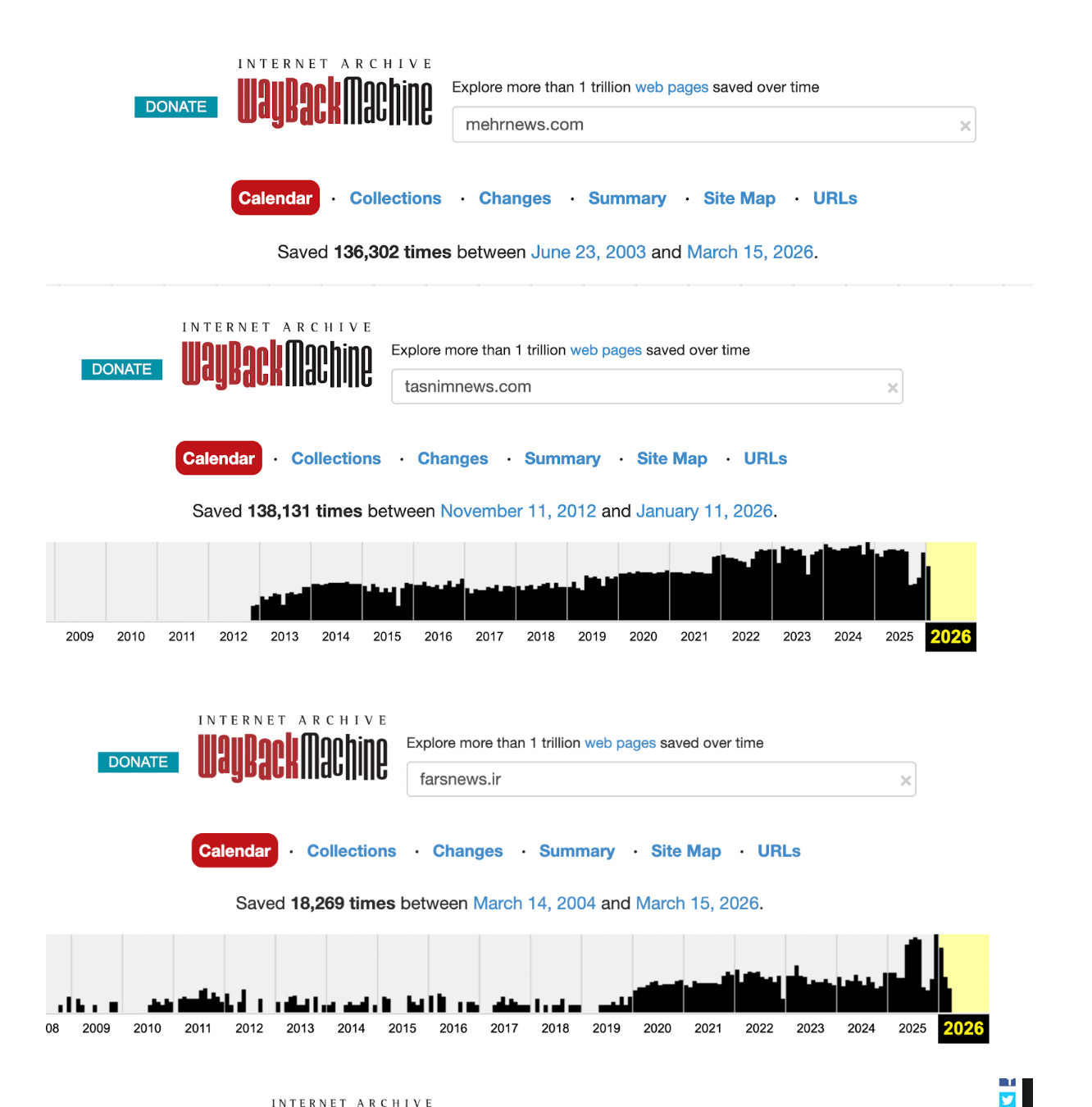
To understand why these sources are consistently available, archival data from the Internet Archive was examined. The Wayback Machine has recorded extensive captures of both mainstream and state-linked outlets:
BBC: 391,548 captures since 1998
Tasnim News Agency: 138,131 captures since 2012
Mehr News Agency: 136,302 captures since 2003
Khamenei.ir: 34,114 captures since 2002
Fars News Agency: 18,269 captures since 2004
These figures show that state media has been consistently indexed and preserved alongside established news organizations for decades, increasing its visibility to search systems and AI models.
These domains have been continuously indexed and preserved for decades. They are embedded within the infrastructure used by search engines and AI systems.
The failure in Claude’s search results mirrors the ones identified in Wikipedia, which relies on open contribution and inconsistent source scrutiny. AI systems rely on automated retrieval and inconsistent source evaluation.
The mechanism is the same. The difference is scale.